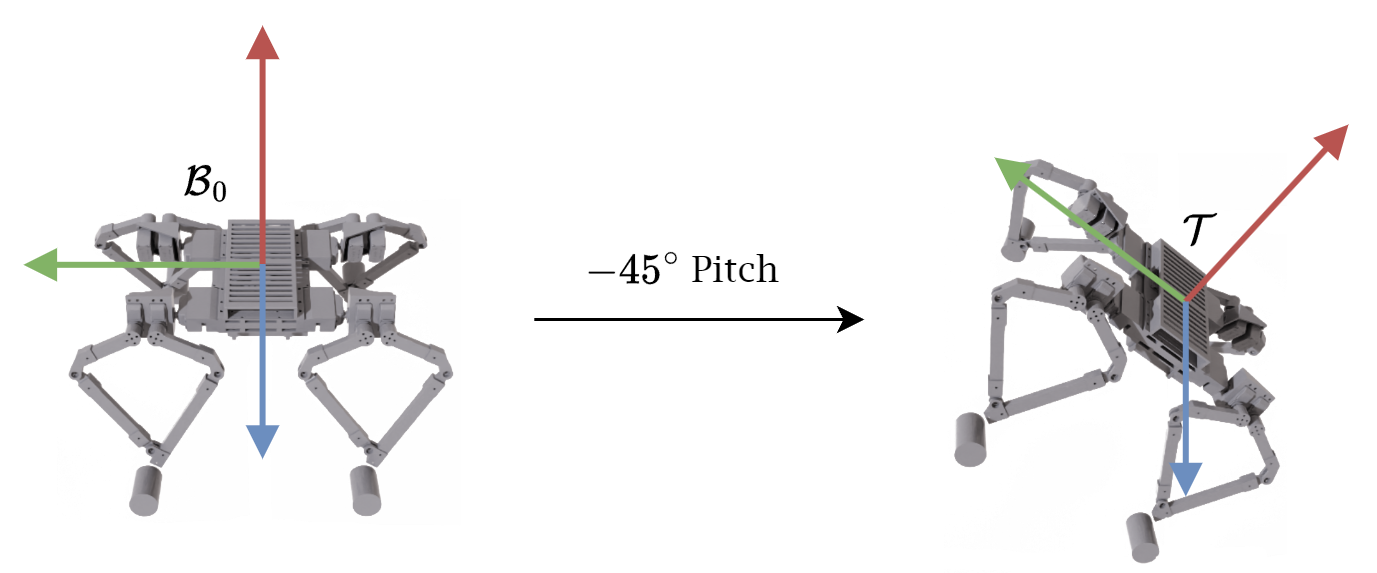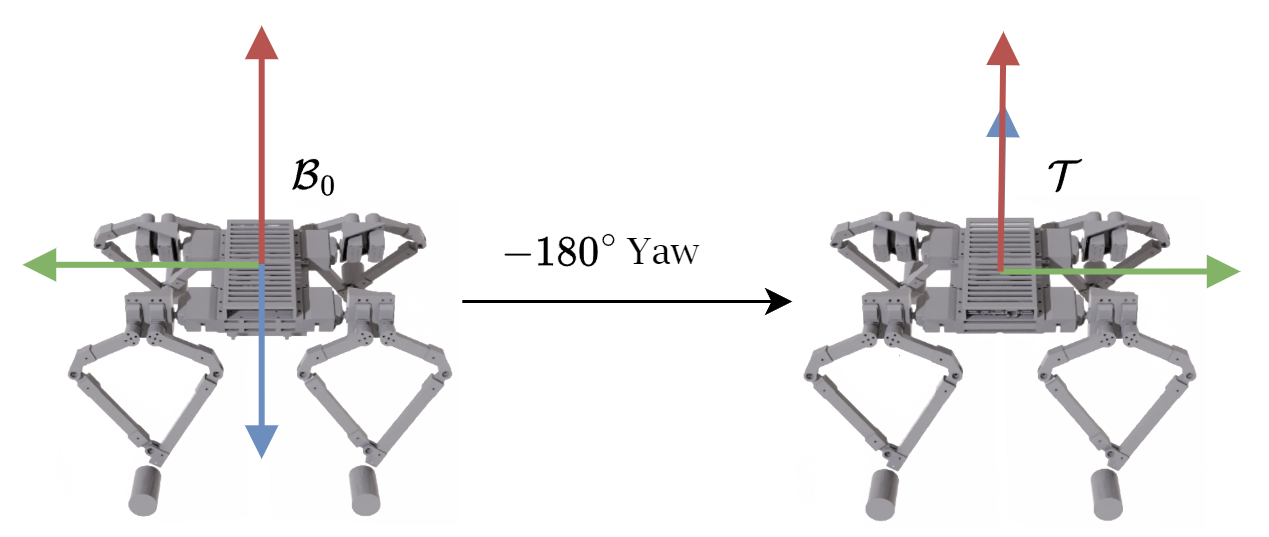Problem Description and Proposed Approach
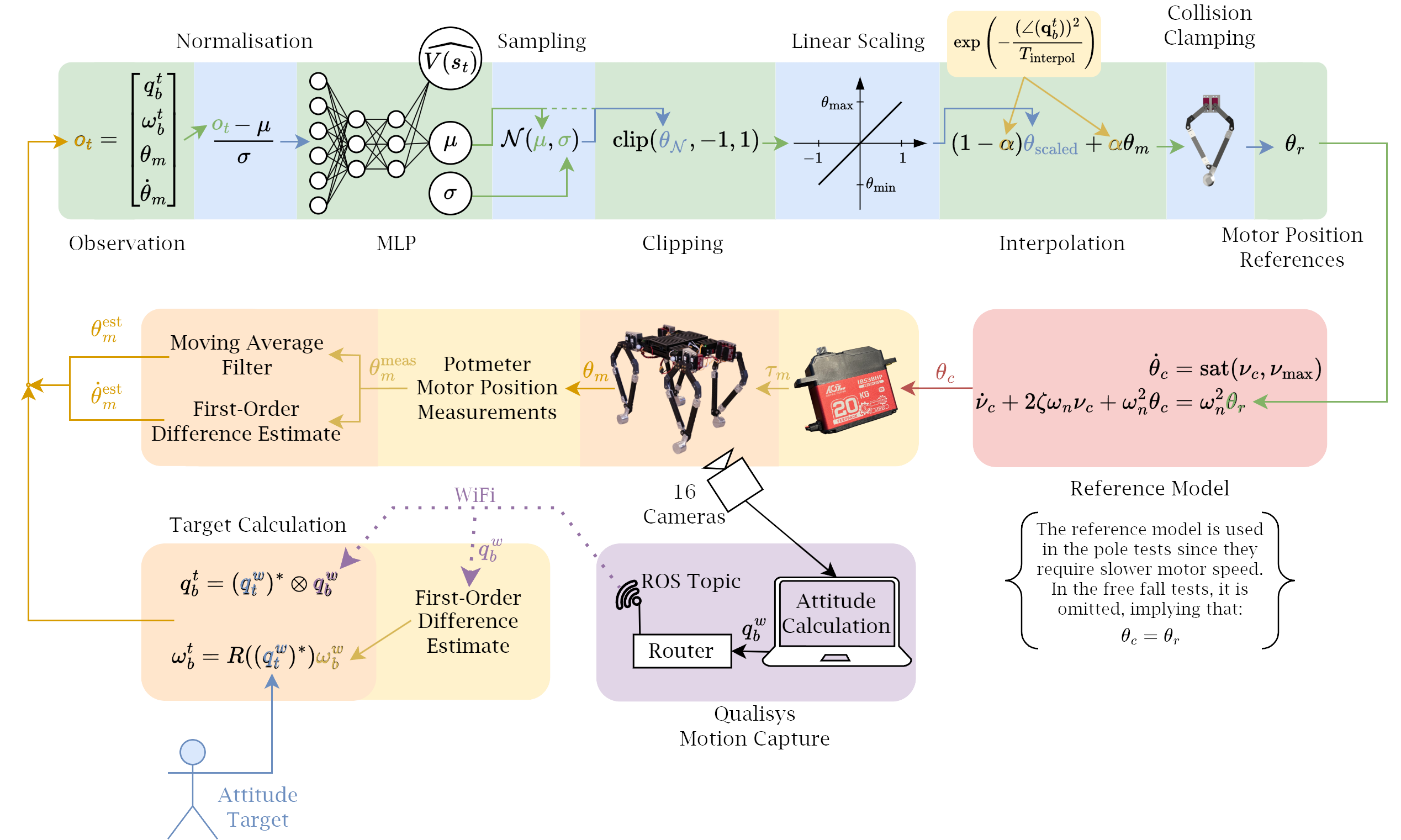
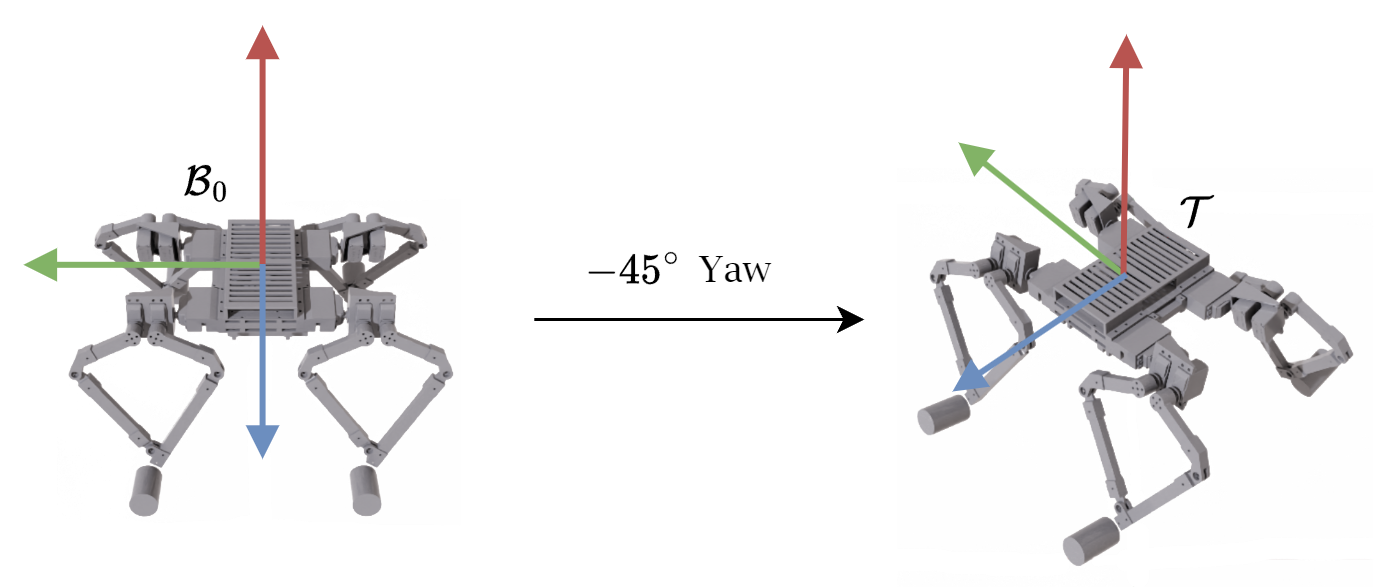
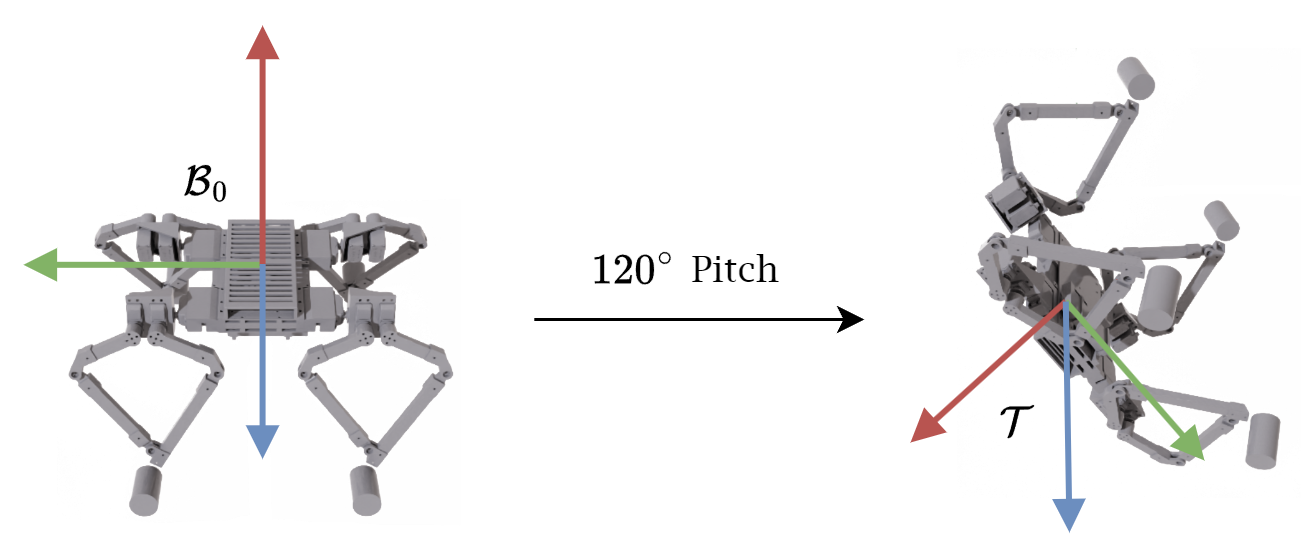
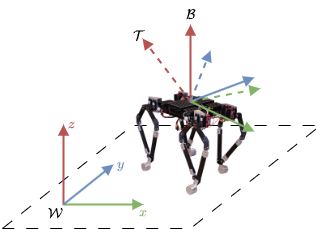
The control problem is described as follows: Given a quadruped with a body-fixed frame \( \mathcal{B} \) and an inertial frame \(\mathcal{W}\), we want to adjust \(\mathcal{B}\) to align with a target frame \(\mathcal{T}\). The target frame \(\mathcal{T}\) has the same origin as \(\mathcal{B}\) but may have a different orientation, as shown in the figure below. We assume the quadruped is "floating" in a zero-gravity environment and that it must reach its target orientation using solely its legs as reaction masses.
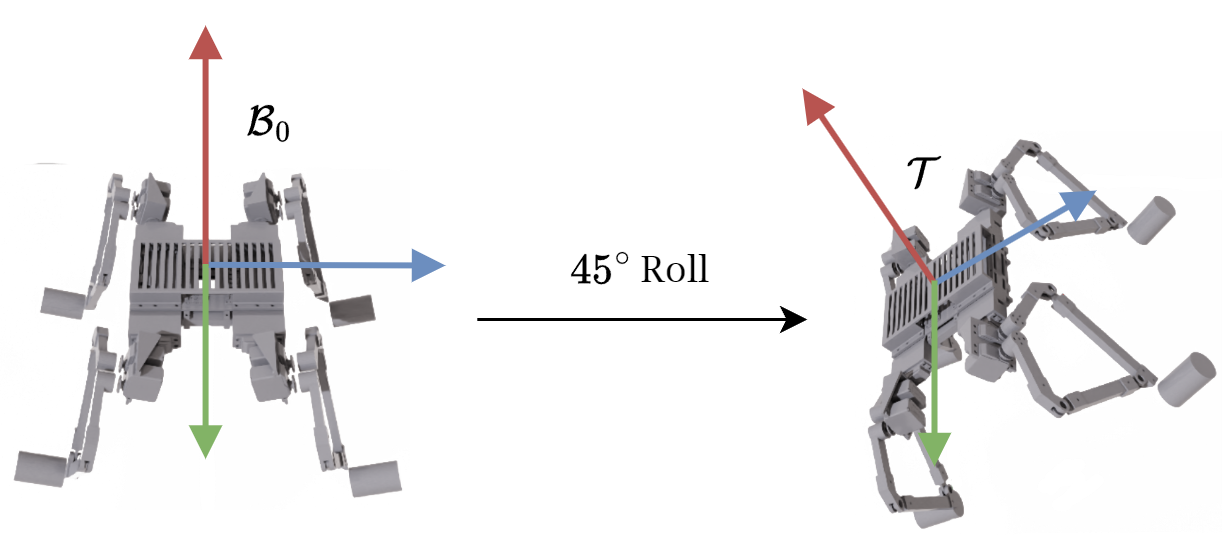
The figure below illustrates the control loop, including the implemented control law or policy. The policy (in blue and green) takes an observation vector as input. This vector consists of the error quaternion \( q^t_b \), which represents the orientation of the body frame relative to the target frame, the angular velocity of the body in the target frame \( \omega^t_b \), and the estimated motor positions and velocities (\(\theta_m, \dot{\theta}_m\)). The multi-layer perceptron has three layers with sizes [128, 64, 64] and uses ELU activation functions. The weights are trained in simulation using PPO. The policy outputs motor position references \(\theta_r\), which are either directly sent to the servo motors or passed through a reference model first. The quadruped's orientation relative to the inertial frame is measured using a Qualisys motion capture system, and the target orientation is set by the user.